



JS爬虫逆向
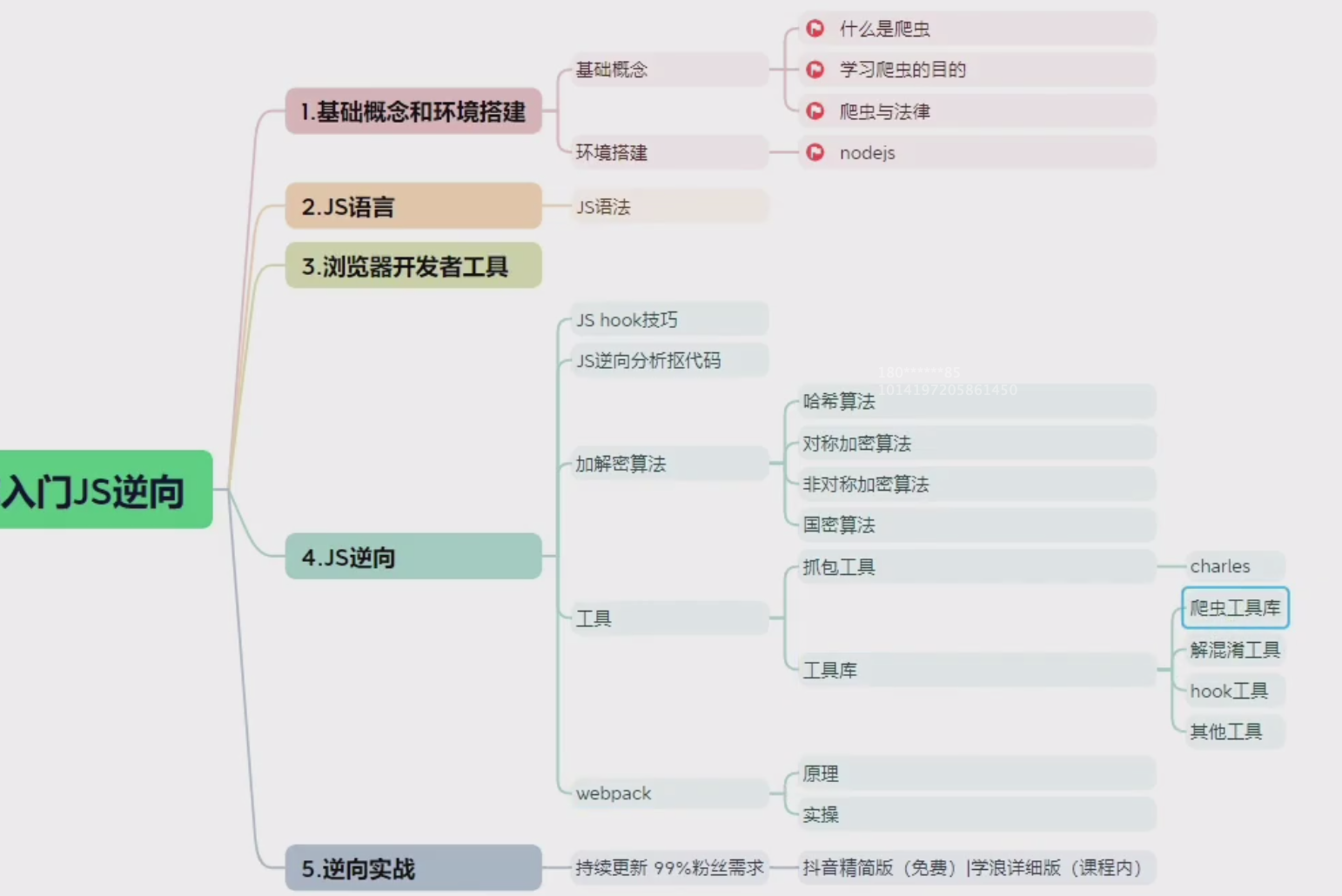
1.基础概念和环境搭建
基础概念
什么是爬虫
正常情况下,人去访问网页,网页返回数据
通过js程序模拟人的行为去获取网页接口的数据
用程序去模拟人!!!
学习爬虫的目的
去获取数据,如果这个网页有几百页几千页,容易把人给累死。所以。
有些公司是做自动化
做兼职。。。
做反爬
爬虫与法律
技术本无罪。
1.不能碰个人信息
2.不能把网站搞down了
3.不能黄赌毒
4.不能不当的商业竞争
5.版权问题
6.网页上没有显示的数据,但是从api接口中获取的,是不能拿下来卖的
7.不能公开分享爬虫等相关的
环境搭建
nodejs
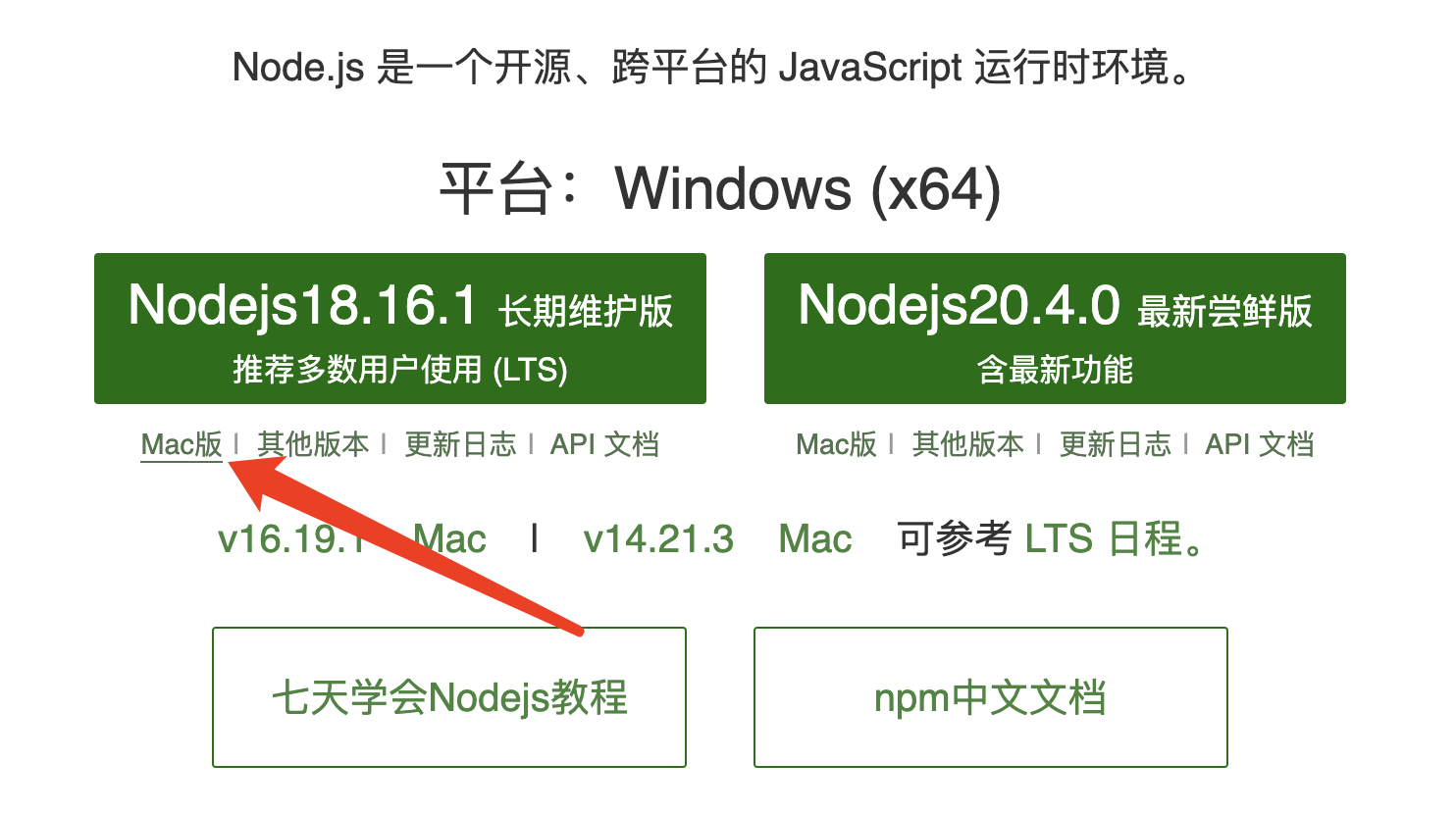 下载安后
下载安后
node 和npm都ok了,还差一个cnpm

安装cnpm
直接安装会报错,证书错误
sudo npm install -g cnpm --registry=https://registry.npm.taobao.org

解决方法
清除npm缓存
npm cache clean --force
取消ssl验证:
npm config set strict-ssl false
之后再npm install 你想安装的东西就可以按照了
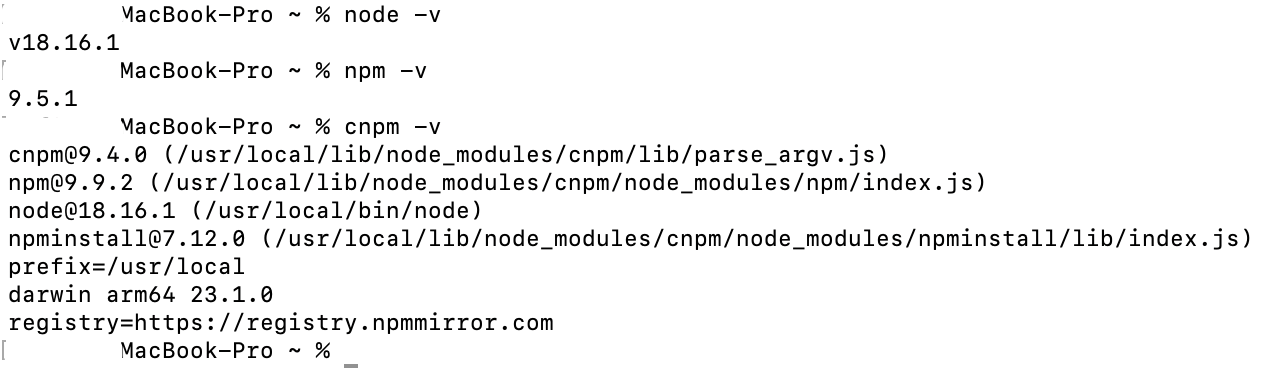
验证
看一下环境是否安装到位
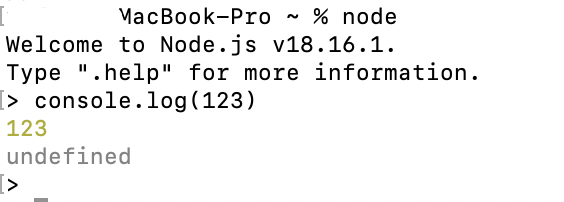
 小试一下~
小试一下~
 为什么使用nodejs
为什么使用nodejs
它是基于ChromeV8引擎的一个js环境,使用一个事件驱动,
非阻塞IO模型,轻量又高效,而且还跨平台。
然后安装vscode
创建一个.js文件
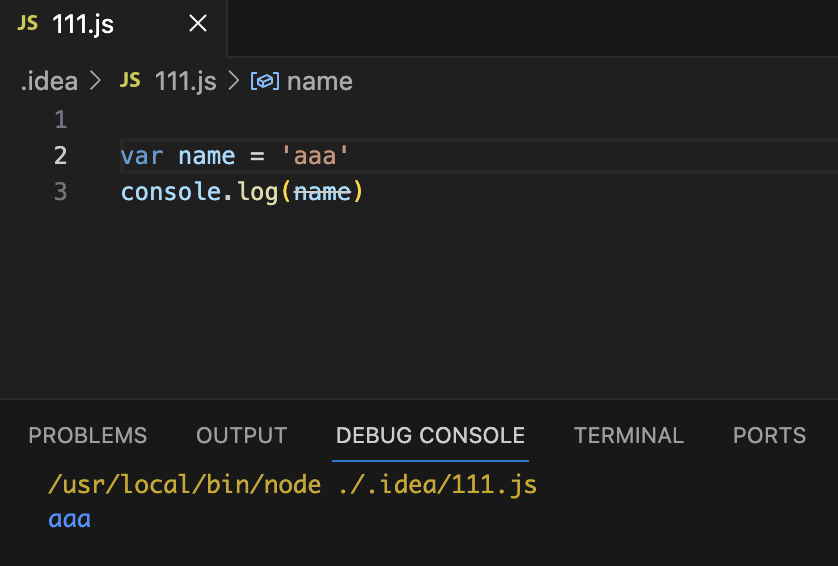 其他的IDE也可以,Pycharm;
其他的IDE也可以,Pycharm;
2.JS语言
JS语法
3.浏览器开发者工具
JS hook技巧
JS逆向分析抠代码
加解密算法
哈希算法
对称加密算法
非对称加密算法
国密算法
4.JS逆向
工具
抓包工具
charles
工具库
爬虫工具库:https://spidertools.cn/#/
解混淆工具
hook工具
其他工具
webpack
原理
实操
5.逆向实战
持续更新
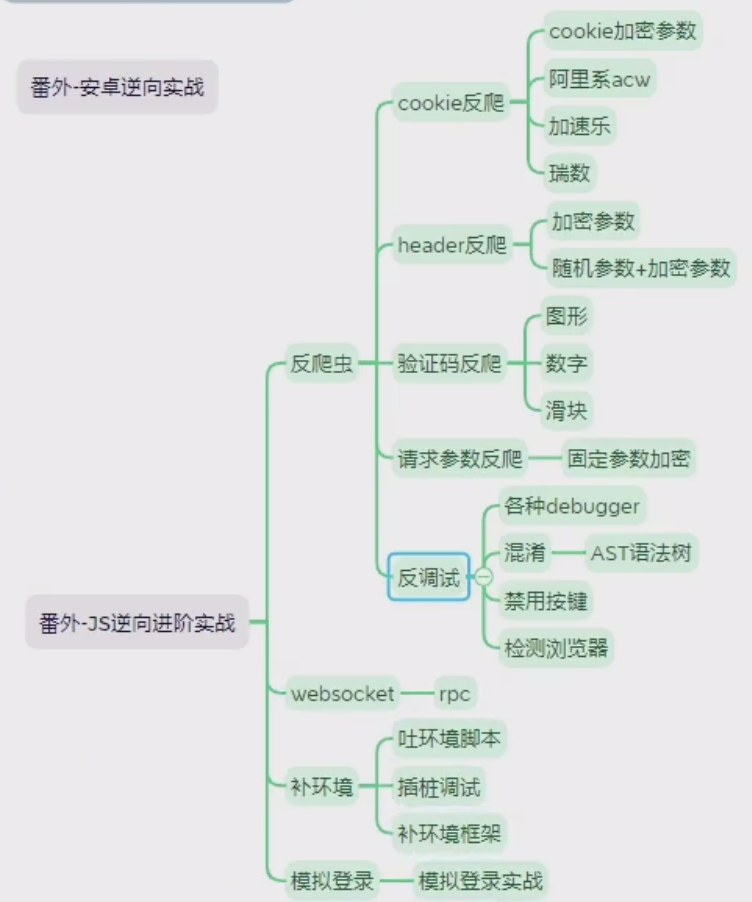
6.逆向进阶
什么是爬虫
-.-
评论区